
MiniMax M2.5
MiniMax M2.5 is a 230B MoE model (10B active) that scores 80.2% on SWE-Bench Verified while costing 1/10th to 1/20th of frontier competitors like Claude Opus 4.6 and GPT-5.2.
MiniMax M2.5 is a 230B MoE model (10B active) that scores 80.2% on SWE-Bench Verified while costing 1/10th to 1/20th of frontier competitors like Claude Opus 4.6 and GPT-5.2.
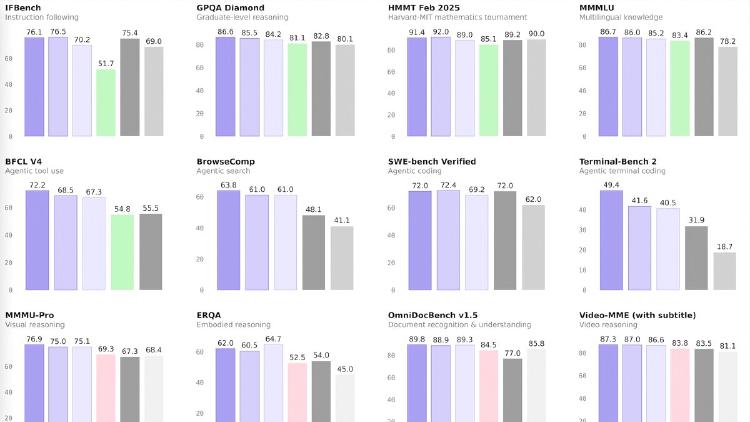
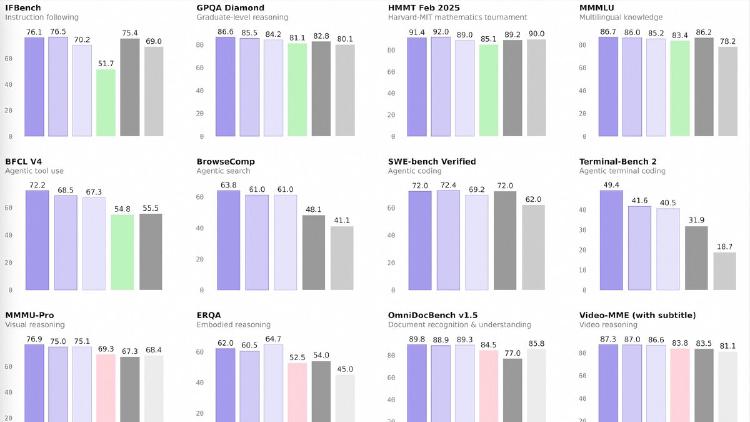
Qwen3.5-122B-A10B is a 122B-parameter MoE model activating 10B parameters per token, narrowing the gap between medium and frontier models with top scores in GPQA Diamond (86.6), MMMU (83.9), and OCRBench (92.1). Apache 2.0 licensed.
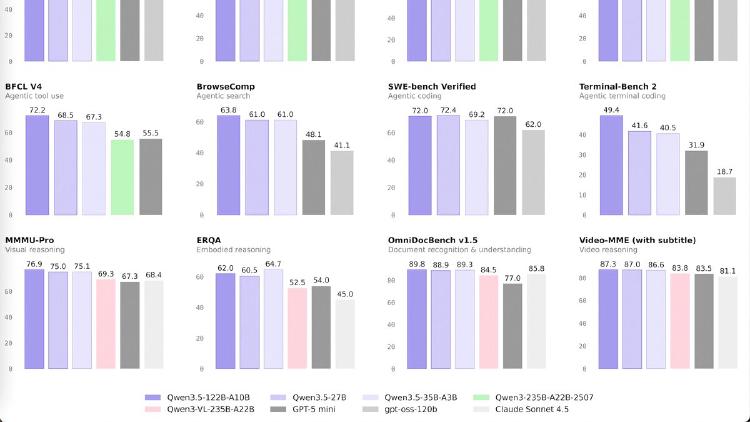
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
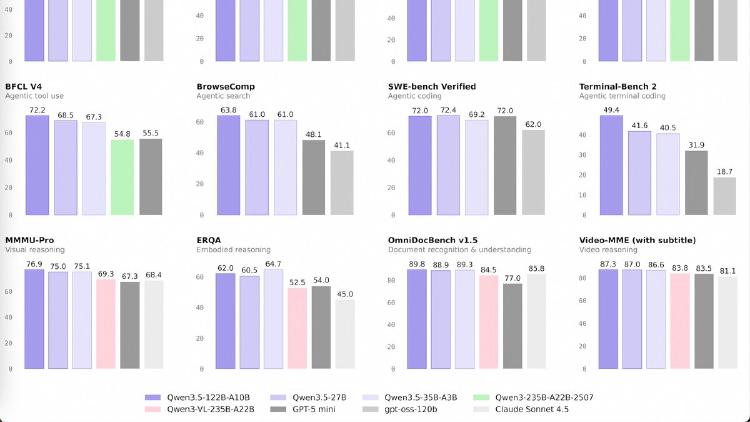
Qwen3.5-35B-A3B is a 35B-parameter MoE model activating just 3B parameters per token that surpasses the previous Qwen3-235B flagship across language, vision, and agent benchmarks. Apache 2.0 licensed.
Qwen3.5-Flash is Alibaba's hosted production model with 1M context, built-in tools, and multimodal support at $0.10/M input tokens - one of the cheapest frontier-tier APIs available.

Anthropic's flagship model leads on agentic coding, enterprise knowledge work, and long-context retrieval with a 1M-token window, 128K output, and agent teams at $5/$25 per million tokens.
