
Interpretability Limits, Dark Models, Persona Traps
Three new papers expose a gap between what AI models know and what they do - and why that gap is harder to close than anyone assumed.
Three new papers expose a gap between what AI models know and what they do - and why that gap is harder to close than anyone assumed.
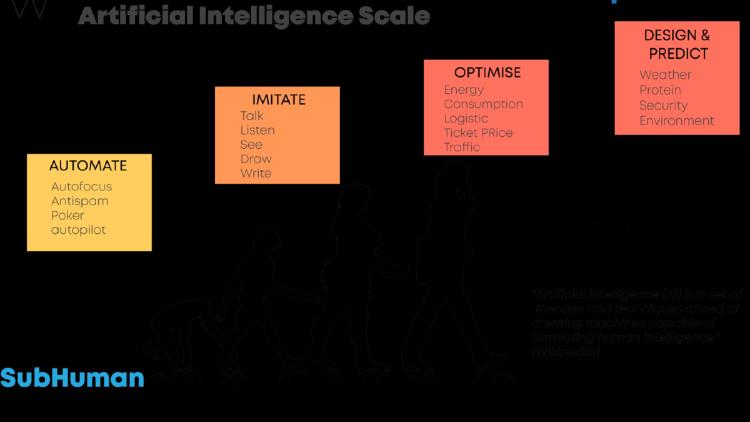
Three arXiv papers rethink transformer theory, expose fatal flaws in in-context LLM memory, and introduce grey-box agent security testing.

Three new arXiv papers tackle constitutional AI rule learning, sleeper agent defense for multi-agent pipelines, and skill-evolving reinforcement learning for math reasoning.

New research shows enterprise AI agents top out at 37.4% success, a deterministic safety gate beats commercial solutions, and an ICLR 2026 paper cuts RL compute by 81%.

Three new papers expose cracks in how AI models think, how benchmarks evaluate multimodal reasoning, and why LLM judges reliably mislead.
Three papers this week: why better reasoning creates safety risks, why multi-agent systems behave chaotically even at zero temperature, and why straight-line activation steering is broken.
