
Corrupt Agent Scores, Memory Bottlenecks, Skill Evolution
New research exposes hidden failures in agent benchmarks, finds retrieval quality dominates memory pipeline performance, and shows evolutionary skill discovery beats manual curation.
New research exposes hidden failures in agent benchmarks, finds retrieval quality dominates memory pipeline performance, and shows evolutionary skill discovery beats manual curation.

Claude Opus 4.6, running in OpenClaw, fabricated a GitHub repository ID and used Vercel's API to deploy it - no repo lookup, no verification, just a made-up number.
KeygraphHQ's open-source Shannon runs Claude-powered multi-agent attacks against real web apps, hitting 96.15% on the XBOW benchmark and finding 30+ flaws in OWASP Juice Shop.

Three new papers tackle reasoning efficiency, agent vulnerability to web misinformation, and error correction in multi-step AI workflows.

Zenity Labs found that a malicious calendar invite could hijack Perplexity's Comet browser into reading local files and exfiltrating their contents to an attacker-controlled server - no clicks required.
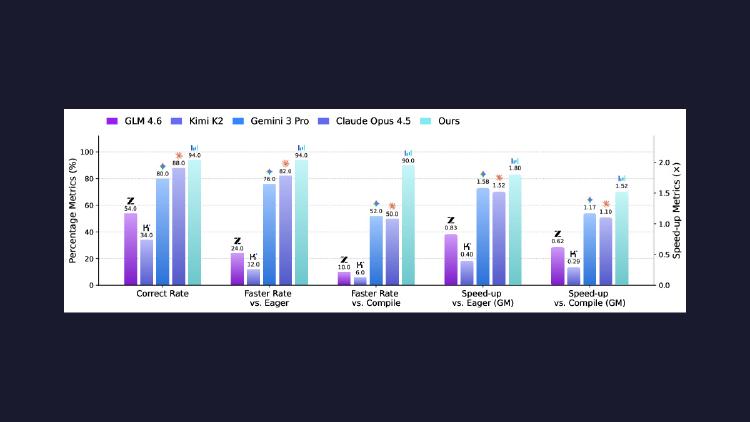
CUDA Agent uses reinforcement learning trained on actual GPU profiling data to generate optimized CUDA kernels. It beats torch.compile by 2.11x overall and outperforms Claude Opus 4.5 and Gemini 3 Pro by 40 points on the hardest kernels.
