
Kimi K2.5 vs Qwen3.5-35B-A3B: Frontier Powerhouse Meets the Tiny Giant Killer
A detailed comparison of Kimi K2.5 and Qwen3.5-35B-A3B - a 1T parameter frontier model with agent swarms versus a 35B model that runs on a single consumer GPU.
A detailed comparison of Kimi K2.5 and Qwen3.5-35B-A3B - a 1T parameter frontier model with agent swarms versus a 35B model that runs on a single consumer GPU.

A benchmark-by-benchmark comparison of Qwen3.5-122B-A10B and DeepSeek V3.2 - the efficiency-optimized underdog versus the brute-force open-source heavyweight.

A data-driven comparison of Alibaba's Qwen3.5-122B-A10B and Meta's Llama 4 Maverick - two open-weight MoE models with radically different approaches to parameter efficiency and benchmark performance.

A data-driven comparison of Qwen3.5-122B-A10B and Mistral Large 3 - two Apache 2.0 MoE models where the smaller one dominates text benchmarks despite a 4x active parameter disadvantage.
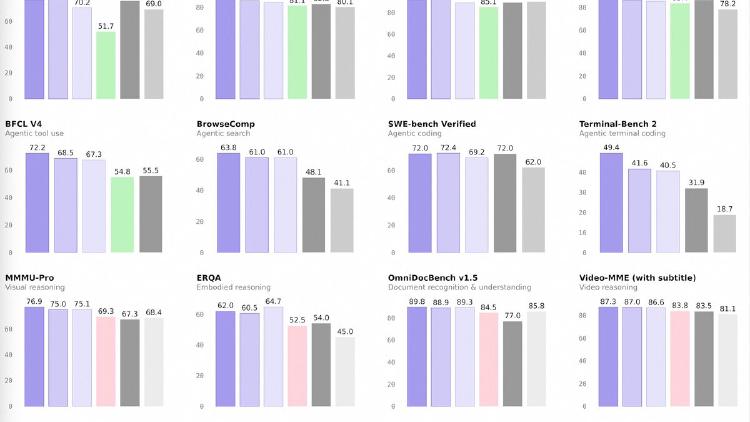
Alibaba releases four Qwen 3.5 medium models - Flash, 35B-A3B, 122B-A10B, and 27B - that match or beat the previous 235B flagship at a fraction of the compute. The 35B model activates just 3 billion parameters and still outperforms Qwen3-235B-A22B.
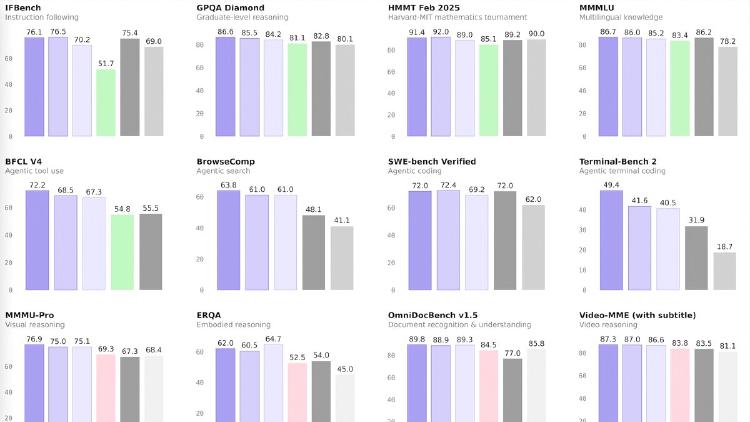
Qwen3.5-122B-A10B is a 122B-parameter MoE model activating 10B parameters per token, narrowing the gap between medium and frontier models with top scores in GPQA Diamond (86.6), MMMU (83.9), and OCRBench (92.1). Apache 2.0 licensed.
