Qwen3.5-27B
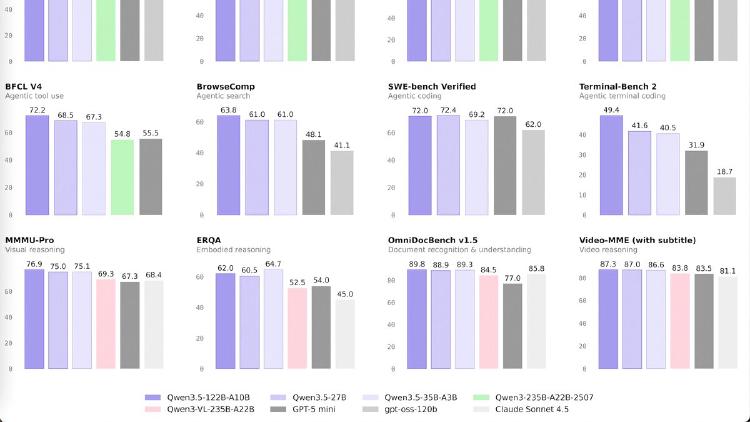
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
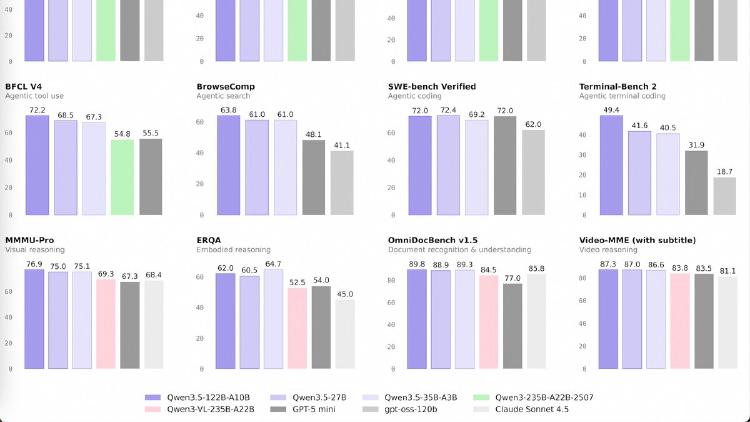
Qwen3.5-35B-A3B is a 35B-parameter MoE model activating just 3B parameters per token that surpasses the previous Qwen3-235B flagship across language, vision, and agent benchmarks. Apache 2.0 licensed.
Qwen3.5-Flash is Alibaba's hosted production model with 1M context, built-in tools, and multimodal support at $0.10/M input tokens - one of the cheapest frontier-tier APIs available.

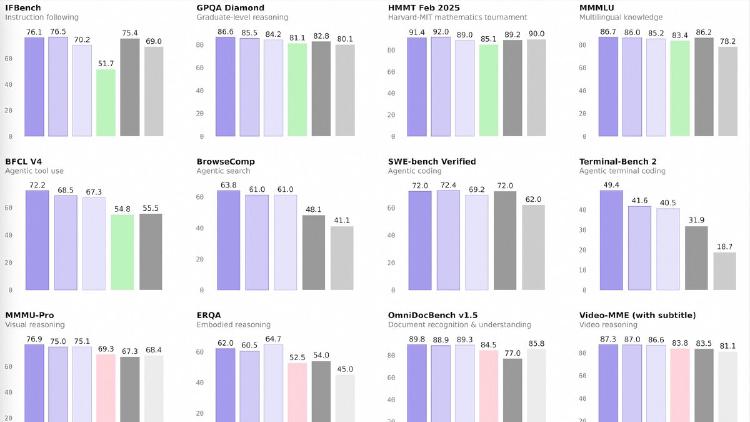
Alibaba's Qwen team releases Qwen3.5-397B-A17B, an open-weight mixture-of-experts model with native multimodal support and a hybrid attention architecture that runs 8x faster than its predecessor. Apache 2.0 licensed.

Alibaba releases Qwen 3.5, a 397-billion-parameter open-weight model that claims to outperform US frontier models at a fraction of the cost.

Alibaba releases Qwen 3.5, a 397B parameter open-source multimodal model with 256K context, Apache 2.0 license, and performance that tops Python coding and math reasoning benchmarks.
