Claude Sonnet 4.6 Review: The Workhorse That Ate the Flagship
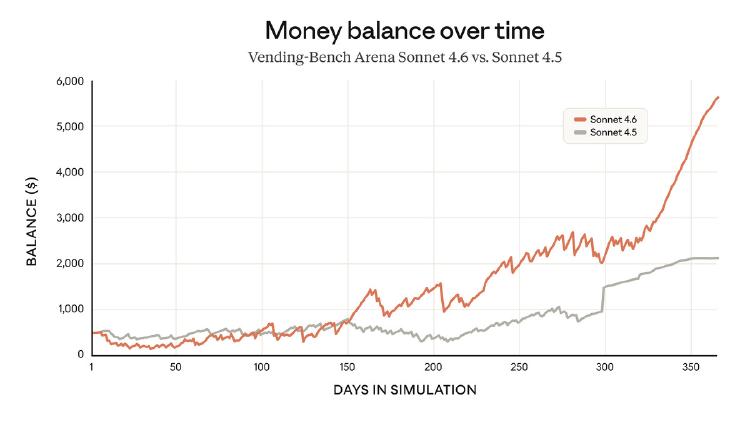
Anthropic's mid-tier model delivers 98% of Opus performance at one-fifth the cost, with a 1M token context window and near-parity on coding and computer use benchmarks.
Anthropic's mid-tier model delivers 98% of Opus performance at one-fifth the cost, with a 1M token context window and near-parity on coding and computer use benchmarks.

Google releases Gemini 3.1 Pro with dramatically improved reasoning, topping Claude Opus 4.6 and GPT-5.2 on most industry benchmarks.

Three papers that matter this week: a brutal benchmark for AI research agents, a feature-space approach to training data diversity, and trace rewriting to stop model theft.

Rankings of the best open source LLMs you can run on home hardware - RTX 4090, RTX 3090, Apple M3/M4 Max - organized by VRAM tier with real-world token/s benchmarks and quality scores.
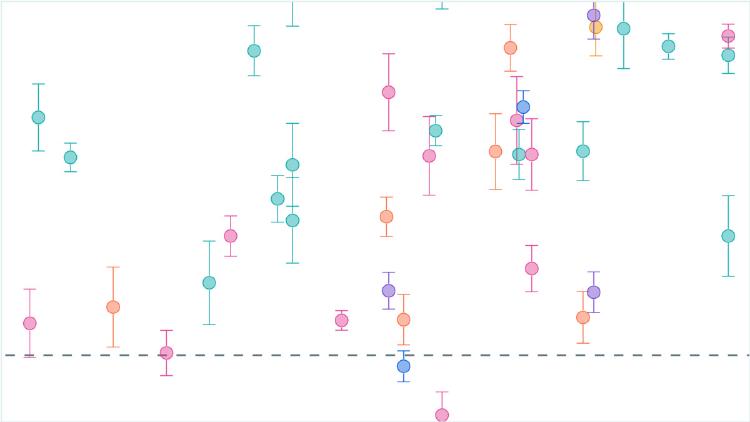
A data-driven look at benchmark contamination, leaderboard gaming, and whether public AI benchmarks can still tell us anything useful about model capabilities.
Rankings of the best AI models for long-context tasks, measuring retrieval accuracy, reasoning, and comprehension across massive context windows from 128K to 10M tokens.
