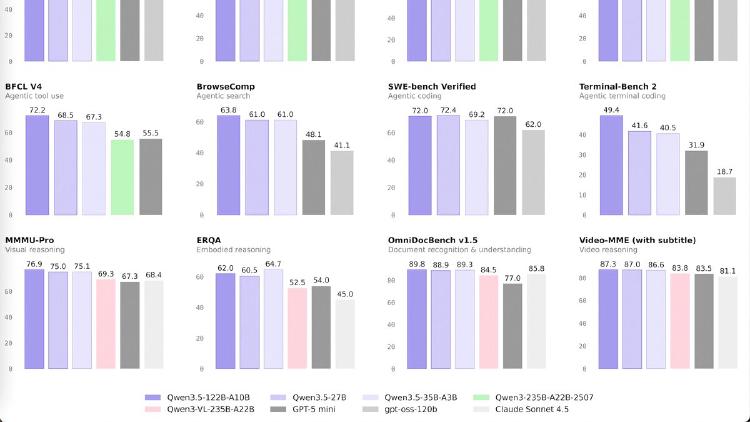
Qwen3.5-27B
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.

Anthropic's flagship model leads on agentic coding, enterprise knowledge work, and long-context retrieval with a 1M-token window, 128K output, and agent teams at $5/$25 per million tokens.

OpenAI's most capable agentic coding model combines frontier code generation with GPT-5-class reasoning, 400K context, and a 77.3% Terminal-Bench 2.0 score.
Anthropic's mid-tier model delivers 98% of Opus performance at one-fifth the cost, with a 1M token context window and near-parity on coding and computer use benchmarks.

How to build a professional AI-assisted coding environment that costs nothing - the best free editors, extensions, inference providers, and local models combined into setups that rival $20/month subscriptions.

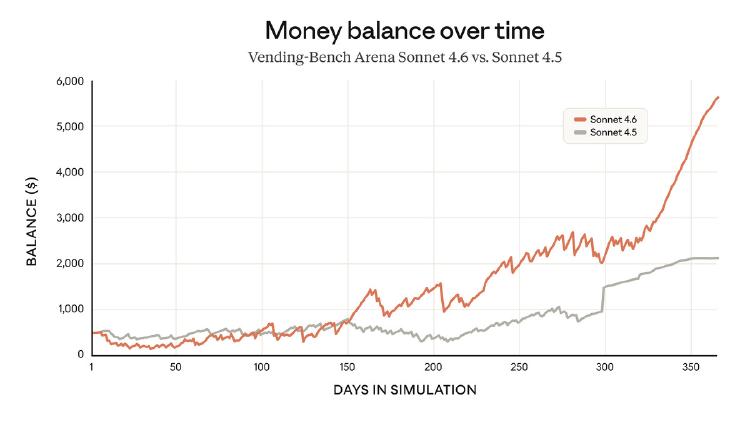
Anthropic's new mid-tier model matches Opus 4.6 on coding benchmarks, ships a million-token context window, and keeps the same $3/$15 pricing as its predecessor.
