
Nemotron-Cascade 2: 30B Open MoE, One GPU, Beats 120B
NVIDIA's new Nemotron-Cascade-2-30B-A3B activates just 3B parameters per token, runs on a single RTX 4090, and outscores NVIDIA's own 120B model on coding and math benchmarks.
NVIDIA's new Nemotron-Cascade-2-30B-A3B activates just 3B parameters per token, runs on a single RTX 4090, and outscores NVIDIA's own 120B model on coding and math benchmarks.

Apple launches M5 Pro and M5 Max MacBook Pros with Neural Accelerators in every GPU core, 128GB unified memory, and 614GB/s bandwidth - enough to run Llama 70B on a laptop.

macOS RDMA over Thunderbolt 5 has turned four Mac Studios into a 1.5TB unified memory cluster that runs Kimi K2 at 25 tokens per second - a setup that would cost $780K with NVIDIA H100s.

LM Studio 0.4.5 introduces LM Link, built on Tailscale's tsnet library, letting users access local AI models on remote hardware through end-to-end encrypted connections with zero port forwarding.

MIT spinoff Liquid AI releases LFM2-24B-A2B, a hybrid mixture-of-experts model that activates only 2.3B parameters per token, fits in 32GB RAM, and hits 112 tokens per second on a consumer CPU.
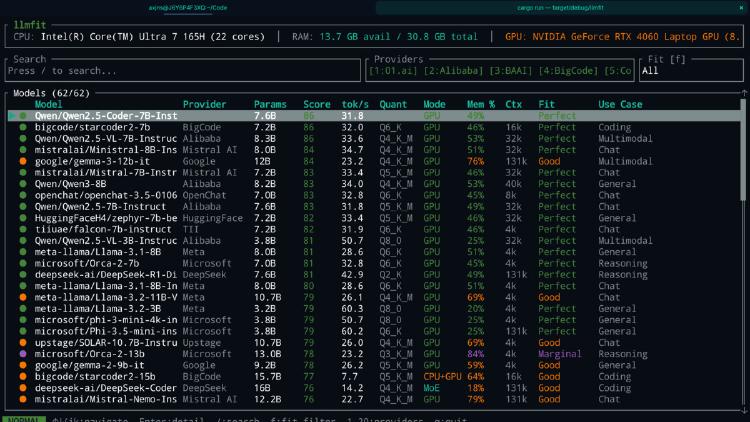
LLMfit is a Rust-based terminal tool that scans your hardware and scores 157 LLMs across 30 providers for compatibility, speed, and quality. Here is why it matters.
