Nemotron 3 Nano 30B-A3B
NVIDIA's hybrid Mamba2+MoE model packs 31.6B total parameters but activates only 3.2B per token, delivering frontier-class reasoning with 3.3x the throughput of comparable models on a single H200 GPU.
NVIDIA's hybrid Mamba2+MoE model packs 31.6B total parameters but activates only 3.2B per token, delivering frontier-class reasoning with 3.3x the throughput of comparable models on a single H200 GPU.
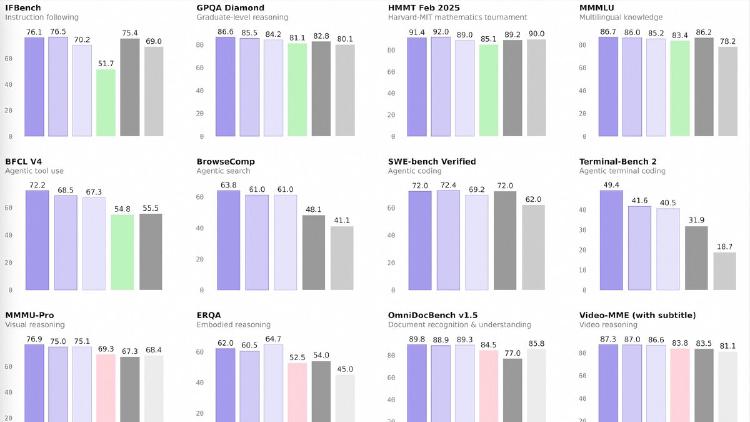
Qwen3.5-Flash is Alibaba's hosted production model with 1M context, built-in tools, and multimodal support at $0.10/M input tokens - one of the cheapest frontier-tier APIs available.
Rankings of the best AI models for long-context tasks, measuring retrieval accuracy, reasoning, and comprehension across massive context windows from 128K to 10M tokens.
