
Llama 4 Maverick
Meta's Llama 4 Maverick packs 400B total parameters into a 128-expert MoE architecture with only 17B active per token, beating GPT-4o on Chatbot Arena while matching DeepSeek V3 on reasoning at half the active parameters.
Meta's Llama 4 Maverick packs 400B total parameters into a 128-expert MoE architecture with only 17B active per token, beating GPT-4o on Chatbot Arena while matching DeepSeek V3 on reasoning at half the active parameters.

Meta's Llama 4 Scout is a 109B-total, 17B-active MoE model with 16 experts and a 10M-token context window - the longest of any open-weight model - with native multimodal support for text and images.

Mistral Large 3 is a 675B-parameter MoE model activating 41B per token with native multimodal support, a 256K context window, and Apache 2.0 licensing - Europe's first frontier-class open-weight model.

Mistral Small 3.2 is a 24B dense model with strong function calling, multimodal vision, and 128K context under Apache 2.0 - optimized for production tool-use pipelines and EU-compliant deployments.

David vs Goliath: Qwen3.5-35B-A3B activates 3B parameters and beats Llama 4 Scout's 17B active on MMLU-Pro, GPQA, and coding benchmarks - but Scout's 10M context window and native multimodal support tell a different story.
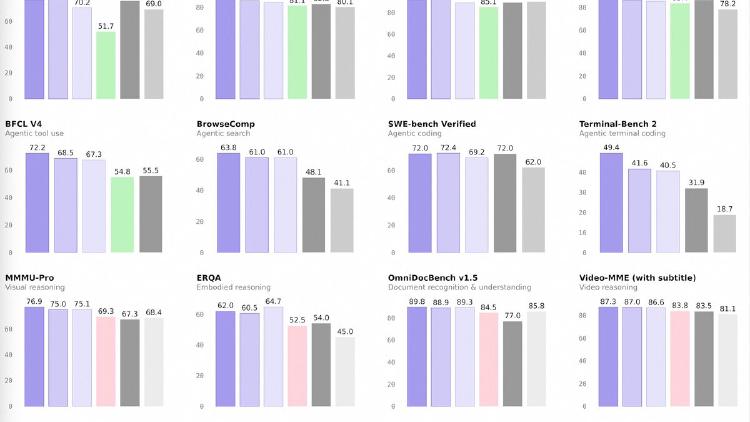
Alibaba releases four Qwen 3.5 medium models - Flash, 35B-A3B, 122B-A10B, and 27B - that match or beat the previous 235B flagship at a fraction of the compute. The 35B model activates just 3 billion parameters and still outperforms Qwen3-235B-A22B.
