Qwen3.5-27B
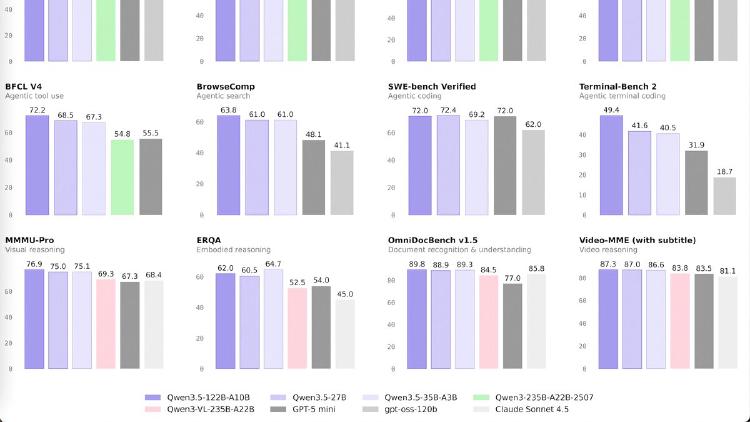
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
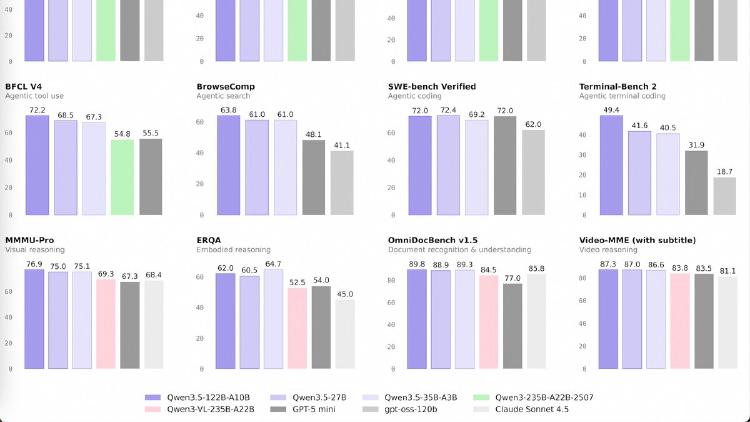
Qwen3.5-35B-A3B is a 35B-parameter MoE model activating just 3B parameters per token that surpasses the previous Qwen3-235B flagship across language, vision, and agent benchmarks. Apache 2.0 licensed.

MIT spinoff Liquid AI releases LFM2-24B-A2B, a hybrid mixture-of-experts model that activates only 2.3B parameters per token, fits in 32GB RAM, and hits 112 tokens per second on a consumer CPU.

YC-backed startup Guide Labs releases Steerling-8B under Apache 2.0 - an 8.4B parameter model with a built-in concept module that traces every output token back to its training data.

Alibaba's Qwen team releases Qwen3.5-397B-A17B, an open-weight mixture-of-experts model with native multimodal support and a hybrid attention architecture that runs 8x faster than its predecessor. Apache 2.0 licensed.
Cohere Labs releases Tiny Aya, a 3.35B open-weight multilingual model that beats Gemma 3 4B in 46 of 61 languages on translation and runs at 32 tokens/sec on an iPhone.
